Hi. ¶
Everything for this workshop is available online here
Fantastic Data and Where To Find Them: An introduction to APIs, RSS, and Scraping ¶
Nicole Donnelly, District Data Labs
Who Are You? ¶
Who Are We? ¶

Tony Ojeda ¶

Will Voorhees ¶

Nicole Donnelly ¶

Agenda ¶
APIs, an introduction¶
- What are APIs?
- Where are APIs?
- How do I access APIs?
- What is the API giving me?
APIs, hands-on¶
- RSS
- REST APIs with Authentication
- Scripting API Calls
Web scraping, an introduction¶
- What is web scraping?
- When should I web scrape?
- How do I web scrape?
Web scraping, hands-on¶
- BeautifulSoup, an overview
- Web scraping, downloading data example
- Web scraping, try it out
Baleen, a case study¶
- How can we operationalization data collection?
What are APIs? ¶
Application Programming Interface ¶
“In the simplest terms, APIs are sets of requirements that govern how one application can talk to another.”
“APIs are what make it possible to move information between programs....”
- APIs make data collection easier!
- Well, until they don't... limited data, rate limiting, financial charges
Where are APIs? ¶

What is RSS? ¶
RSS ¶
“RSS is an XML-based vocabulary for distributing Web content in opt-in feeds. Feeds allow the user to have new content delivered to a computer or mobile device as soon as it is published. ”
Source: http://searchwindevelopment.techtarget.com/definition/RSS
There are different versions - RSS 1.0, RSS 2.0, ATOM
- RSS 1.0: RDF (Resource Description Framework) Site Summary
- RSS 2.0: Really Simple Syndication, based on RSS 0.91
- ATOM: functionally similar, but is a formal specification from Internet Engineering Task Force (IETF)
Additional information on RSS: https://www.mnot.net/rss/tutorial/
Is RSS an API? ¶
"RSS is in some sense a specific API in its own right – with specific semantics for calls (the “latest” X items on this topic) and standard formats for the data being returned. This makes the content from this API accessible to many thousands of reader implementations."
How do I access RSS and APIs? ¶
Context: I will focus on RSS and REST APIs with JSON.
Read more about API types here
RSS ¶
http://dvd.netflix.com/NewReleasesRSS
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom" >
<channel >
<title>New Releases This Week</title>
<ttl>10080</ttl>
<link>http://dvd.netflix.com</link>
<description>New movies at Netflix this week</description>
<language>en-us</language>
<cf:treatAs xmlns:cf="http://www.microsoft.com/schemas/rss/core/2005">list</cf:treatAs>
<atom:link href="http://dvd.netflix.com/NewReleasesRSS" rel="self" type="application/rss+xml"/>
<item>
<title>Bakery in Brooklyn</title>
<link>https://dvd.netflix.com/Movie/Bakery-in-Brooklyn/80152426</link>
<guid isPermaLink="true">https://dvd.netflix.com/Movie/Bakery-in-Brooklyn/80152426</guid>
<description><a href="https://dvd.netflix.com/Movie/Bakery-in-Brooklyn/80152426"><img src="//secure.netflix.com/us/boxshots/small/80152426.jpg"/></a><br>Vivien and Chloe have just inherited their Aunt's bakery, a boulangerie that has been a cornerstone of the neighborhood for years. Chloe wants a new image and product, while Vivien wants to make sure nothing changes. Their clash of ideas leads to a peculiar solution, they split the shop in half. But Vivien and Chloe will have to learn to overcome their differences in order to save the bakery and everything that truly matters in their lives.</description>
</item>
Context: I will focus on RSS and REST APIs with JSON.
Read more about API types here
API ¶
http://dev.markitondemand.com/Api/Quote/json?symbol=AAPL
{"Data":{"Status":"SUCCESS","Name":"Apple Inc","Symbol":"AAPL","LastPrice":117.12,"Change":-0.349999999999994,"ChangePercent":-0.297948412360598,"Timestamp":"Wed Oct 19 00:00:00 UTC-04:00 2016","MarketCap":631094444160,"Volume":20034594,"ChangeYTD":105.26,"ChangePercentYTD":11.2673380201406,"High":117.76,"Low":113.8,"Open":117.25}}

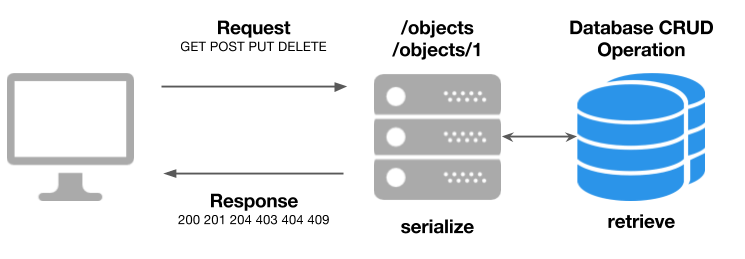
HTTP Status Codes¶
- 1xx - Informational
- 2xx - Success
- 3xx - Redirection
- 4xx - Client Error
- 5xx - Server Error
A complete list can be found here: HTTP Statuses.
A response of 200 Ok means that the request was successful. Other common status codes include:
- 404 Not Found: the requested path does not exist on the server
- 500 Server Error: something went very wrong on the server
- 301 Redirect: the resource has moved to a different URL
- 403 Forbidden: the resource requires authentication
http://api.dp.la/v2/items?api_key=0123456789&q=goats+AND+cats
{"count":29,
"start":0,
"limit":10,
"docs":[{"@context":"http://dp.la/api/items/context","isShownAt":"http://cdm16795.contentdm.oclc.org/cdm/ref/collection/divtour/id/88","dataProvider":"Missouri State Archives through Missouri Digital Heritage","@type":"ore:Aggregation","provider":{"@id":"http://dp.la/api/contributor/missouri-hub","name":"Missouri Hub"},"hasView":{"@id":"http://cdm16795.contentdm.oclc.org/cdm/ref/collection/divtour/id/88"},"object":"http://data.mohistory.org/files/thumbnails/cdm16795_contentdm_oclc_org568ad334407e0.jpg","ingestionSequence":12,"id":"9e05f398ca95f9bbfd733e6d3493fd74","ingestDate":"2016-10-11T13:21:48.399681Z","_rev":"7-6bee4d18708d1d16efceeea1e061b316","aggregatedCHO":"#sourceResource","_id":"missouri--urn:data.mohistory.org:mdh_all:oai:cdm16795.contentdm.oclc.org:divtour/88","sourceResource":{"title":["Alabama Big Cats Safari Adventure"],"description":["Children bottle feeding goats"],"subject":[{"name":"Transparencies, Slides"},{"name":"Tourist Destination"}],"rights":["Copyright is in the public domain. Items reproduced for publication should carry the credit line: Courtesy of the Missouri State Archives."],"relation":["Division of Tourism Photograph Collection"],"language":[{"iso639_3":"eng","name":"English"}],"format":"Image","collection":{"id":"594a2b3666ab0c55245f6640555554cd","description":"","title":"Mdh_divtour","@id":"http://dp.la/api/collections/594a2b3666ab0c55245f6640555554cd"},"stateLocatedIn":[{"name":"Missouri"}],"@id":"http://dp.la/api/items/9e05f398ca95f9bbfd733e6d3493fd74#sourceResource","identifier":["001_070","http://cdm16795.contentdm.oclc.org/cdm/ref/collection/divtour/id/88"],"creator":["GD"]},"admin":{"validation_message":null,"sourceResource":{"title":"Alabama Big Cats Safari Adventure"},"valid_after_enrich":true},"ingestType":"item","@id":"http://dp.la/api/items/9e05f398ca95f9bbfd733e6d3493fd74","originalRecord":{"id":"urn:data.mohistory.org:mdh_all:oai:cdm16795.contentdm.oclc.org:divtour/88","provider":{"@id":"http://dp.la/api/contributor/missouri-hub","name":"Missouri Hub"},"collection":{"id":"594a2b3666ab0c55245f6640555554cd","description":"","title":"mdh_divtour","@id":"http://dp.la/api/collections/594a2b3666ab0c55245f6640555554cd"},"header":{"expirationdatetime":"2016-10-08T17:04:17Z","datestamp":"2016-10-04T13:19:05Z","identifier":"urn:data.mohistory.org:mdh_all:oai:cdm16795.contentdm.oclc.org:divtour/88","setSpec":"mdh_divtour"},"metadata":{"mods":{"accessCondition":"Copyright is in the public domain. Items reproduced for publication should carry the credit line: Courtesy of the Missouri State Archives.","location":{"url":[{"#text":"http://cdm16795.contentdm.oclc.org/cdm/ref/collection/divtour/id/88","access":"object in context"},{"#text":"http://data.mohistory.org/files/thumbnails/cdm16795_contentdm_oclc_org568ad334407e0.jpg","access":"preview"}]},"subject":[{"topic":"Transparencies, Slides"},{"topic":"Tourist Destination"}],"name":{"namePart":"GD","role":{"roleTerm":"creator"}},"relatedItem":{"titleInfo":{"title":"Division of Tourism Photograph Collection"}},"physicalDescription":{"note":"Image"},"xmlns":"http://www.loc.gov/mods/v3","language":{"languageTerm":"eng"},"titleInfo":{"title":"Alabama Big Cats Safari Adventure"},"identifier":["001_070","http://cdm16795.contentdm.oclc.org/cdm/ref/collection/divtour/id/88"],"note":["Children bottle feeding goats",{"#text":"Missouri State Archives through Missouri Digital Heritage","type":"ownership"}]}}},"score":4.534843}, ...
"facets":[]}
For the purposes of this tutorial, you will see info in the notebook on creating a json file with your keys. If you follow a naming convention for your API key files, you can easily add them to your .gitignore file to avoid inadvertantly uploading them to git.
What is the API giving me? ¶
http://dev.markitondemand.com/Api/Quote/json?symbol=AAPL
{"Data":{"Status":"SUCCESS","Name":"Apple Inc","Symbol":"AAPL","LastPrice":117.06,"Change":-0.0600000000000023,"ChangePercent":-0.0512295081967233,"Timestamp":"Thu Oct 20 00:00:00 UTC-04:00 2016","MarketCap":630771137580,"Volume":24059570,"ChangeYTD":105.26,"ChangePercentYTD":11.2103363100893,"High":117.38,"Low":116.33,"Open":116.86}}
http://dev.markitondemand.com/Api/Quote/xml?symbol=AAPL
<QuoteApiModel>
<Data>
<Status>SUCCESS</Status>
<Name>Apple Inc</Name>
<Symbol>AAPL</Symbol>
<LastPrice>117.06</LastPrice>
<Change>-0.06</Change>
<ChangePercent>-0.0512295082</ChangePercent>
<Timestamp>Thu Oct 20 00:00:00 UTC-04:00 2016</Timestamp>
<MarketCap>630771137580</MarketCap>
<Volume>24059570</Volume>
<ChangeYTD>105.26</ChangeYTD>
<ChangePercentYTD>11.2103363101</ChangePercentYTD>
<High>117.38</High>
<Low>116.33</Low>
<Open>116.86</Open>
</Data>
</QuoteApiModel>
Summary ¶
- APIs provide access to data
- APIs return serialized data
- APIs are everywhere
- RSS is an API
What is web scraping? ¶
- Web Scraping goes by many names - Screen Scraping, Web Data Extraction, Web Harvesting
- It is the process of directly accessing webpages to copy data when APIs are not provided
- It automates the process of copying the data and saving it locally
- It can be a vioation of terms of service
- It can have legal repercussions
- Even when it isn't a violation/ illegal, it is ethically ambiguous
- It can look like a DOS and can overwhelm resources making them unavailable to others
- Scraping needs to be customized for each site
When should I web scrape? ¶
"IF YOU NEED A SCRAPER, YOU HAVE A DATA PROBLEM."¶
David Eads, PyData DC, 10/9/16¶
Useful Scraping Techniques¶
NEVER SCRAPE UNLESS YOU...¶
- have no other way of liberating the data
- budget appropriately
- consider the ethical ramifications (do some googling and read about the ethics)
- read terms of service and do your legal research
- talk to a lawyer (if you possibly can)

How do I web scrape? ¶
robots.txt ¶
The robots exclusion standard, also known as the robots exclusion protocol or simply robots.txt, is a standard used by websites to communicate with web crawlers and other web robots. The standard specifies how to inform the web robot about which areas of the website should not be processed or scanned. Robots are often used by search engines to categorize web sites. Not all robots cooperate with the standard; email harvesters, spambots, malware, and robots that scan for security vulnerabilities may even start with the portions of the website where they have been told to stay out. The standard is different from, but can be used in conjunction with, Sitemaps, a robot inclusion standard for websites.
Source: Wikipedia
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
There are a lot of libraries availble in Python to help with this task:
- urllib2 - module for processing urls, expanded in Python 3
- requests - improved upon urllib/ urllib2
- lxml - extensive library for parsing XML and HTML, some people find it a little more difficult to use initially
- beautifulsoup4 - library for pulling data out of HTML and XML files
There is usually more than one way to do things in Python. What you end up with tends to be what you learn first and/ or what you are most comfortable with.
Expect a fair bit of trial and error. Web scraping is not straightforward and not for the faint of heart. It is a last resort.
Summary ¶
- Web scraping is hard
- Web scraping can have legal and ethical implications
- Try to respect robots.txt
- Web scraping can get you some good data

Interested in More from District Data Labs? ¶
DDL PyCon Schedule¶
Talks¶
Friday 4:30 p.m.–5 p.m.
Building A Gigaword Corpus: Lessons on Data Ingestion, Management, and Processing for NLP
Saturday 2:35 p.m.–3:05 p.m.
Human-Machine Collaboration for Improved Analytical Processes
Posters¶
Sunday Morning, Expo Hall
On the Hour Data Ingestion from the Web to a Mongo Database
Model Management Systems: Scikit-Learn and Django
Yellowbrick: Steering Scikit-Learn with Visual Transformers
A Framework for Exploratory Data Analysis with Python
Development Sprints¶
Stay in touch! ¶
Nicole¶
- Twitter: @NicoleADonnelly
- GitHub: nd1
- LinkedIn: nicoleadonnelly
- Email: Nicole Donnelly
Tony¶
- Twitter: @TonyOjeda3
- GitHub: ojedatony1616
- LinkedIn: tonyojeda
- Email: Tony Ojeda
Will¶
- Twitter: @will2041
- GitHub: will2041
- LinkedIn: willvoorhees
- Email: Will Voorhees